The Dependency Inversion Principle “D”
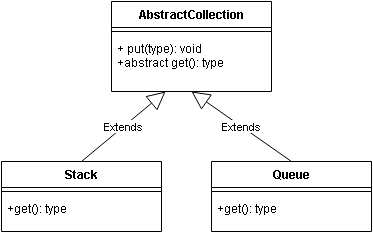
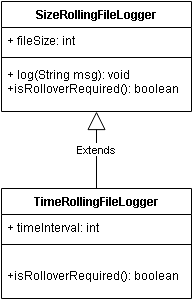
High Level Modules should not depend on low level modules. Both should depend on abstractions.
Abstractions should not depend on details. Details should depend on abstractions.
Overview
The word inversion is a misfit in the 2020s but it has some history around it. Most software were developed using procedural methodologies in the 80s and 90s; in this approach high level business functionalities are broken into low level reusable functions. Although this approach creates good reusable low level functions but it makes high level business functions to require rework when any change is done in low level functions. The term dependency ‘inversion’ was used in the late 90s to say that low level modules should depend on high level modules (main business function) via abstraction in Object Oriented Analysis & Design.
Thus, inverting the way dependencies should be defined is called Dependency Inversion.
Layered Design
A good software architecture defines different layers with specific responsibilities. The bottom layers are more generic & reusable and functionalities tend to become more specific to business use cases as we move up the layers. E.g.
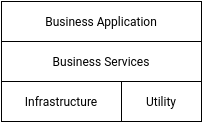
- The lowest layer contains Infrastructure or Utilities like file handling, DB repo, security.
- The middle layer contains reusable business services or models. The functionalities defined here are business functions which are independent of business use cases.
- The top layer contains business use cases which are orchestrated using the middle layer. These are the functionalities understood by users of the application.
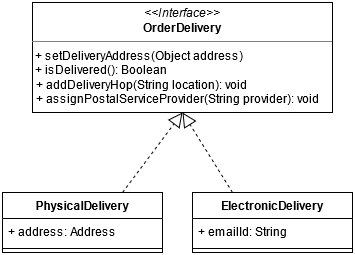
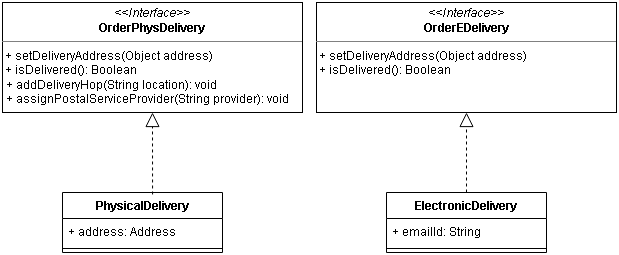
The different layers are defined in different classes, packages/namespaces but they are still tightly coupled. To reduce the coupling and enable higher reuse of Business Services, Different layers can invoke the concrete classes via abstraction, like in the Figure-2:
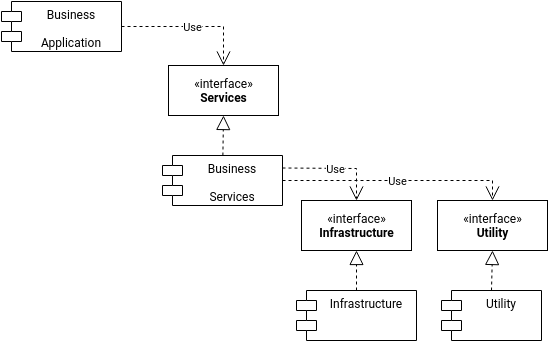
Conclusion
Defining module dependencies via Abstraction helps in maintaining low coupling while keeping the code reusable.
Proper implementation of Dependency Inversion principle requires a broad understanding of the Domain for which application is being developed. The key decision is to segregate functionality between middle layer (reusable business services) and top layer (business user cases).