Introduction
Software developers strive to write functionally working code by self-analysis and brainstorming with peers to cover all possible use-cases which may occur in real world (post the deployment of the application).
In Enterprise Application development there are many methodologies & processes to ensure that the application works as per the Requirements & Functional Specifications. Assuming, functional specifications are as per User requirements.
Enterprise Applications are long living creatures expected to survive years and sometimes decades. They are expected to go through cycles of evolution using bug-fixes, enhancements, integration with other applications, removal of obsolete functionalities.
Therefore, it is important to develop a code that is:
- Maintainable
- Robust
- Scalable
At times, these aspects of the code are not obvious but can be achieved by asking the right questions.
Example Application (Step 1)
Let’s start with a functionally working piece of code and improve it step by step.
Please refer to the two classes Person and PersonManager:
public class Person {
private String firstName;
private String lastName;
private String gender;
public Person(String firstName, String lastName, String gender) {
super();
this.firstName = firstName;
this.lastName = lastName;
this.gender = gender;
}
/*
* Getters and Setters
*/
}
public class PersonManager {
public static void main(String[] args) {
List<Person> people = new ArrayList<>();
Person p1 = new Person("Alan", "Turing", "Male");
people.add(p1);
Person p2 = new Person("Joan", "Clarke", "Female");
people.add(p2);
Person p3 = new Person("James", "Gosling", "Male");
people.add(p3);
for(Person p : people) {
System.out.print(getValue(p.getGender()));
System.out.println(" " + p.getFirstName() + " " + p.getLastName());
}
}
private static String getValue(String input) {
if(input.equalsIgnoreCase("Male")) {
return "Mr";
} else {
return "Ms";
}
}
}
Although an application which doesn’t take any input from Users or External sources like a DB is not very useful, but let’s stick to it for the sake of simplicity and being to the point on writing the clean code.
For complete code of the initial application, please refer https://gitlab.com/saurabhjain1537/refactoring_workshop/-/tree/master/workshop/src/main/java/com/citra/workshop/person/step1
Maintainability (Step 2)
Let’s think about few questions.
- Is this code easy to understand for someone else ?
- If I come back to this code after 6 months, can I recall what I did with a quick glance ?
Although these questions seem easy but practically it takes a bit of experience to answer them honestly. Initially it’s worth taking help from peers & colleagues and get honest feedback from some one trustworthy.
Another way is to self-review a functionality which was developed a few months ago.
Let’s analyze this method:
private static String getValue(String input) {
if(input.equalsIgnoreCase("Male")) {
return "Mr";
} else {
return "Ms";
}
}
This method is taking Gender as input and returning a salutation based on the value. This method will be easier to understand if we rename it to getSalutation and rename the method argument to gender. Something like:
private static String getSalutation(String gender) {
String salutation = null;
if(gender.equalsIgnoreCase("Male")) {
salutation = "Mr";
} else {
salutation = "Ms";
}
return salutation;
}
Analyze this loop:
for(Person p : people) {
System.out.print(getValue(p.getGender()));
System.out.println(" " + p.getFirstName() + " " + p.getLastName());
}
This loop is printing Full Name with salutation, it makes sense to create a method getFullName and invoke it from the loop:
for(Person p : people) {
System.out.println(getFullName(p));
}
}
private static String getFullName(Person p) {
return getSalutation(p.getGender()) + " " + p.getFirstName() + " " + p.getLastName();
}
The complete PersonManager class after refactoring (from Step 1 to Step 2) to make the code more readable, understandable and maintainable:
public class PersonManager {
public static void main(String[] args) {
List<Person> people = new ArrayList<>();
Person alan = new Person("Alan", "Turing", "Male");
people.add(alan);
Person joan = new Person("Joan", "Clarke", "Female");
people.add(joan);
Person james = new Person("James", "Gosling", "Male");
people.add(james);
for(Person p : people) {
System.out.println(getFullName(p));
}
}
private static String getFullName(Person p) {
return getSalutation(p.getGender()) + " " + p.getFirstName() + " " + p.getLastName();
}
private static String getSalutation(String gender) {
String salutation = null;
if(gender.equalsIgnoreCase("Male")) {
salutation = "Mr";
} else {
salutation = "Ms";
}
return salutation;
}
}
For complete code after refactoring for Maintainability, please refer https://gitlab.com/saurabhjain1537/refactoring_workshop/-/tree/master/workshop/src/main/java/com/citra/workshop/person/step2
Robustness (Step 3)
Enterprise Applications interact with multiple Actors like:
- Users via Web interface or Notifications
- Storage systems like DB or File system
- Other applications via messaging queues
A robust application is the one which handles errors due to User input, failure in other systems and report back to the Actors meaningfully.
Few questions to improve robustness:
- Does the application validates every input from Actors ?
- For Input and Internal processing issues, does it responds with meaningful messages ?
- Can anyone easily identify the Module & Functionality causing an issue by analyzing the logs ?
Let’s analyze this method:
private static String getSalutation(String gender) {
String salutation = null;
if(gender.equalsIgnoreCase("Male")) {
salutation = "Mr";
} else {
salutation = "Ms";
}
return salutation;
}
It returns the salutation “Ms” for every gender string that is not “Male”. Even in case of misspelled gender or garbage input like “xyz”, it assumes non-Male and return the salutation “Ms” .
It will make more sense if it validates the Gender to be either “Male” or “Female”. There can be a Gender enum containing valid values and a custom exception class PersonValidationException to specify error scenario:
public enum Gender {
Male,
Female;
}
public class PersonValidationException extends RuntimeException{
public PersonValidationException(String arg0, Throwable arg1) {
super(arg0, arg1);
}
public PersonValidationException(String arg0) {
super(arg0);
}
}
Now getSalutation method can be refactored as:
private static String getSalutation(Gender gender) {
String salutation = null;
if(Gender.Male == gender) {
salutation = "Mr";
} else if(Gender.Female == gender) {
salutation = "Ms";
} else {
throw new PersonValidationException("Unsupported Gender " + gender);
}
return salutation;
}
Person class can be refactored to validate the mandatory fields and dis-allow changes in the member variables values by declaring them as final:
public class Person {
private final String firstName;
private final String lastName;
private final Gender gender;
public Person(String firstName, String lastName, Gender gender) {
if(firstName == null || lastName == null || gender == null) {
throw new IllegalArgumentException("Mandatory Parameter missing.");
}
this.firstName = firstName;
this.lastName = lastName;
this.gender = gender;
}
/*
* Getters
*/
}
For complete code after refactoring for Robustness, please refer https://gitlab.com/saurabhjain1537/refactoring_workshop/-/tree/master/workshop/src/main/java/com/citra/workshop/person/step3
Scalability (Step 4)
Enterprise Applications evolve very fast with lots of enhancements. Developers cannot foresee what is going to come-up in future. Still, they can design the application in ways that (a) makes adding of new features & functionalities simple and (b) decreases the impact on already-working features.
There are lots of techniques that can help in designing scalable software like SOLID principles and Design Patterns. Each one of those deserve a separate article, so to keep things simpler in this article we can make just one improvement.
Let’s analyze the following two methods in PersonManager class:
private static String getFullName(Person p) {
return getSalutation(p.getGender()) + " " + p.getFirstName() + " " + p.getLastName();
}
private static String getSalutation(Gender gender) {
String salutation = null;
if(Gender.Male == gender) {
salutation = "Mr";
} else if(Gender.Female == gender) {
salutation = "Ms";
} else {
throw new PersonValidationException("Unsupported Gender " + gender);
}
return salutation;
}
These methods have improved a lot and they seem good now. Still, few questions to consider:
- Should these methods be part of PersonManager class?
- What if some other class using Person class needs to represent the Person data in similar manner? Will it make sense to duplicate the code ?
- Is getFullName() performing any business function in PersonManager? Isn’t it just another way Person data is represented?
To allow re-usability of code and to keep only relevant code in every class, these methods can be moved from PersonManager to Person class:
public class Person {
private final String firstName;
private final String lastName;
private final Gender gender;
public Person(String firstName, String lastName, Gender gender) {
if(firstName == null || lastName == null || gender == null) {
throw new IllegalArgumentException("Mandatory Paramater missing.");
}
this.firstName = firstName;
this.lastName = lastName;
this.gender = gender;
}
/*
* Getters
*/
public String getSalutation() {
String salutation = null;
if(Gender.Male == gender) {
salutation = "Mr";
} else if(Gender.Female == gender) {
salutation = "Ms";
} else {
throw new PersonValidationException("Unsupported Gender " + gender);
}
return salutation;
}
public String getFullName( ) {
return getSalutation() + " " + getFirstName() + " " + getLastName();
}
}
For complete code after refactoring for Scalability, please refer https://gitlab.com/saurabhjain1537/refactoring_workshop/-/tree/master/workshop/src/main/java/com/citra/workshop/person/step4
Conclusion
In this Example application, we started with a piece of code which was functionally working and was providing valid & expected output. Step by step, we improved the quality of code while keeping the same functionality working all the time.
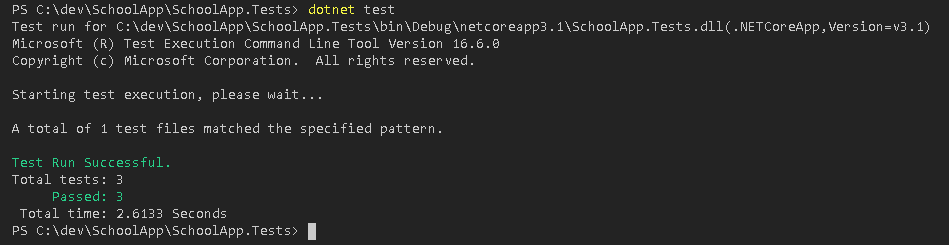
While refactoring an existing code, it is a prerequisite to understand the functionality completely and write comprehensive automated test cases. Execute the automated tests at each step to be sure of retaining the functionality while making the implementation future ready.